
14,700 new subscription apps per month. Seven times more than four years ago. The market has gotten crowded, and the rules keep shifting. What is the best strategy for teams entering or growing in subscriptions in this environment?
Below, we break down how MVP standards have changed in 2026, which approaches seem to work on the way to product-market fit (and which create an illusion of progress), and share how Talaboos runs internally: how we select ideas, build MVPs, and structure the process from hypothesis to the decision to scale or stop.
TL;DR
Building has gotten easier. Winning has gotten harder. AI collapsed the barrier to entry, competition surged, and users became more selective. In these conditions, the teams that test hypotheses faster seem to reach product-market fit sooner than those who spend months polishing a single idea.
But is building an MVP that actually validates an idea as straightforward as it sounds? What should it include, what quality bar is enough, and how do you tell a real signal from misleading early metrics?
We look at two dominant approaches to MVP quality standards, propose a working formula (MVS + MLR) that has been delivering results in our practice, and share the process and systems that help us speed up MVP creation and idea selection. Inside: fresh data from Adapty, RevenueCat, and FunnelFox reports, quotes from the Talaboos team, and specific frameworks you can apply.
In this article, we will cover
- MVP for subscription apps in 2026: what changed
- Vibe-coded MVP vs Minimum Lovable Product: two approaches to product quality standards
- MVP = MVS + MLR: a working formula for subscription products
- Speed of testing vs quality of assumptions
- MVP Factory and Scale Lab: building a system for fast product testing
- How to prioritize product hypotheses
- Subscription app market in 2026: key insights from recent reports
MVP for subscription apps in 2026: what changed
Two years ago, building a subscription app typically required months of development, a dedicated team, and a budget that hurt to lose. That world looks different now.
Vibe coding was named Collins Dictionary's Word of the Year. According to a Stack Overflow 2025 Developer Survey, 84% of developers use or plan to use AI tools, with 51% of professionals using them daily. Gartner projects 75% of enterprise engineers will use AI code assistants by 2028. Platforms like Cursor, Replit, Bolt.new, and Lovable let you ship a working prototype over a weekend. One person with AI tools now covers work that used to require a team of five (Aparna Sinha, SVP of Product at Vercel, a company valued at $9.3B, has said this directly).
What does this mean for subscription products?
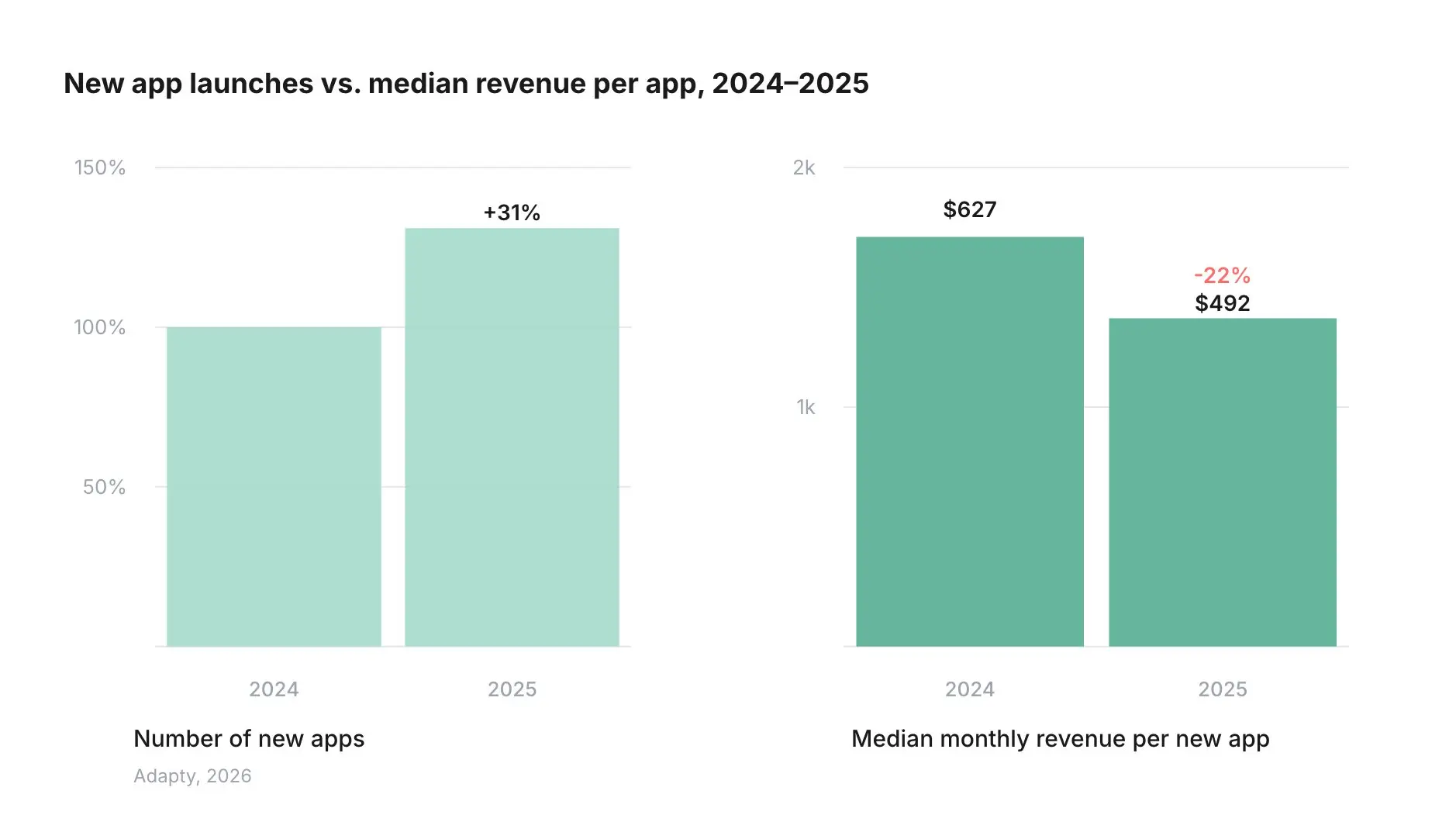
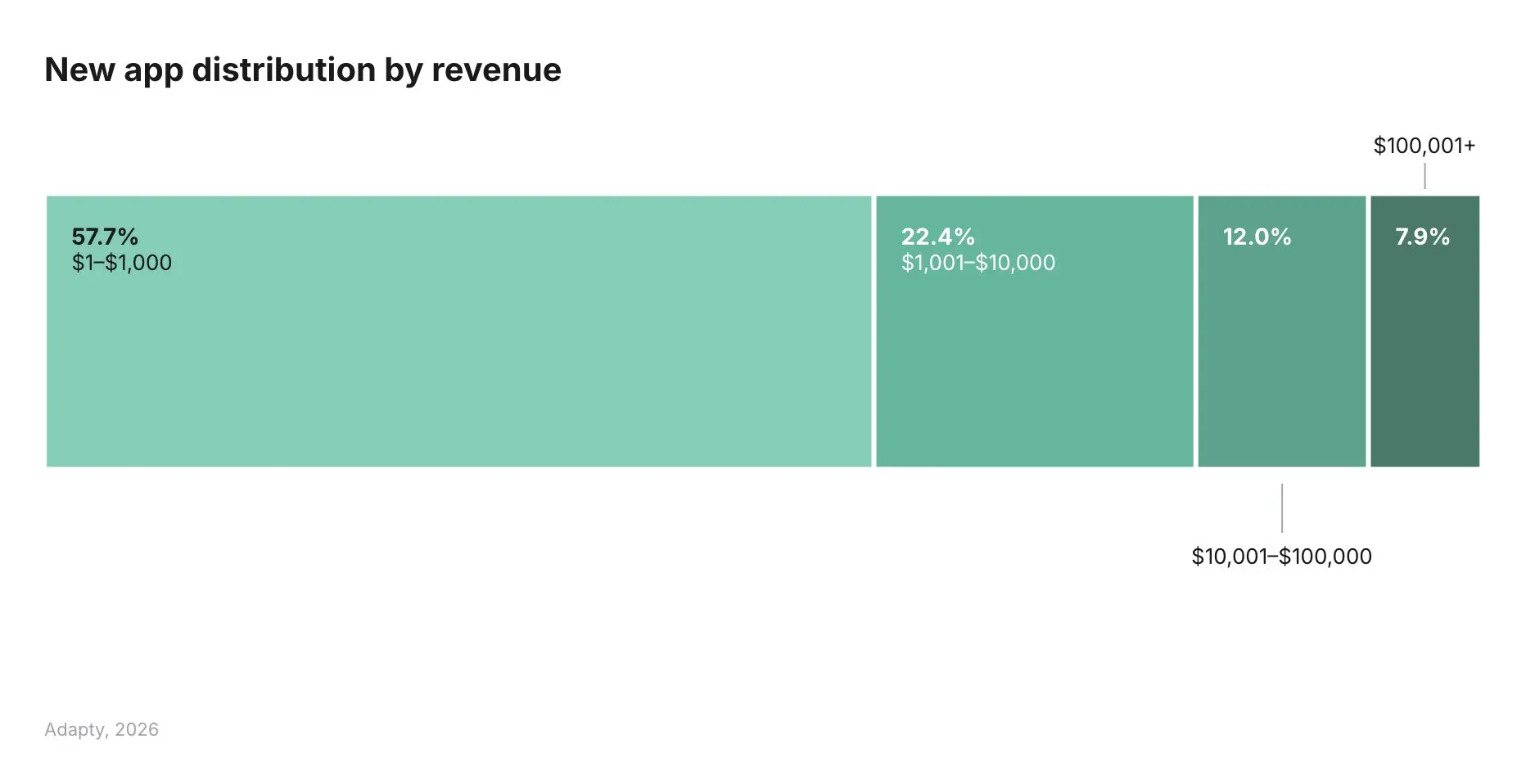
The barrier to entry has collapsed. There are teams running live subscription products that are fully vibe-coded, with no developers in the traditional sense. They are hiring for growth and monetization, not engineering. The product is already live, already acquiring traffic, and already running paywall experiments. That is the new baseline. Working software used to be a competitive advantage ("we actually managed to build this"). Now it is table stakes. Over the past year, the number of subscription apps grew 31%, while the bottom 25% of apps lost 33% of revenue year-over-year (RevenueCat, 2026). More apps, less money per app. 8 out of 10 new apps never break $10K in revenue, and only 7.2% reach $100K (Adapty, 2026).
Speed has become the decisive factor. Stories are already circulating of solo founders and students vibe-coding in weeks what used to take a professional developer months. Whether or not every one of those stories holds up, the direction is clear: the advantage is shifting from "ability to build" to "ability to evaluate and choose." The number of attempts per unit of time matters more than the quality of any single attempt.
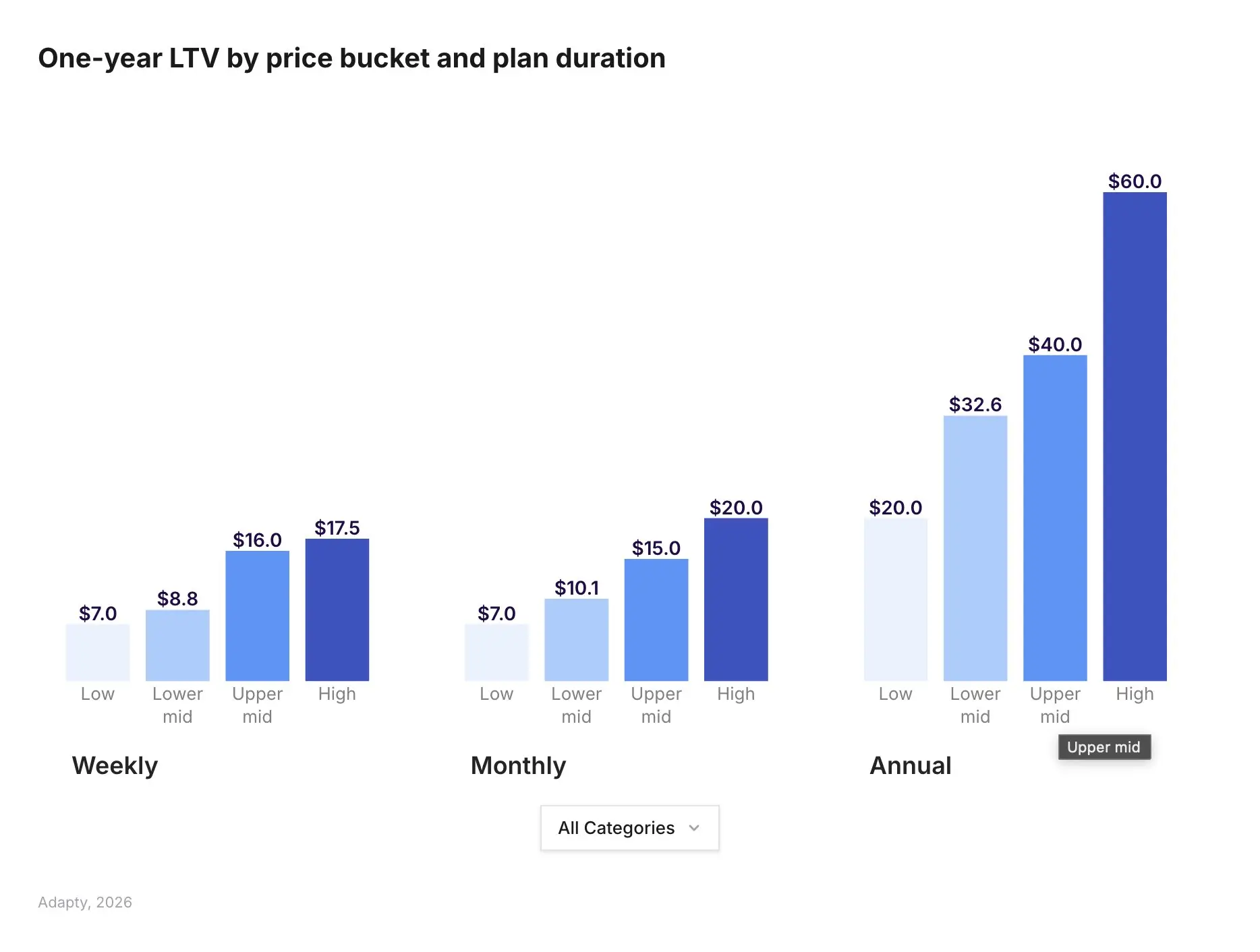
Users have become more selective. Overall conversions and renewals are drifting down, but products with premium pricing are holding their line. High-price apps earn up to 3x the LTV of low-price ones (Adapty, 2026). Price works as a quality signal rather than a commitment barrier. People are willing to pay more, but only for products that nail value delivery in the first few seconds. A mediocre product at a mid-range price sits in the most dangerous zone: too expensive to ignore, too forgettable to keep.
Bottom line: building got easier, winning got harder. Which raises the real question: have the standards for MVP actually changed?
Vibe-coded MVP vs Minimum Lovable Product: two approaches to product quality standards
Two positions have emerged in the industry, each with its own logic and blind spots.
Camp A: MVP is dead, long live MLP (Minimum Lovable Product)
"MVP devolved into minimal functioning product. That world is gone. AI collapsed the cost of building."
— Elena Verna, Head of Growth at Lovable, ex-Miro, ex-Amplitude, ex-Dropbox
The argument is strong. If a product "just works," that is no longer impressive. Users compare against the best experience in the category. Sometimes against "an AI service that does everything for me." In B2C subscriptions with paid UA, a mediocre product quickly becomes an expensive product: CPA climbs, payment conversion drops, refund and chargeback risks increase (especially with aggressive offers).
The trap: MLP as a slogan often turns into "let's keep polishing." Teams lose sight of the core purpose of MVP, which is getting evidence quickly and cheaply. Polishing without data is procrastination.
Camp B: product quality is secondary, testing speed and marketing win
This approach exists, and there is real logic behind it. The cost of building has dropped, so the advantage goes to whoever produces more iterations: more creatives, more funnels, more tests on pricing, paywalls, and onboarding. Subscription economics are often "made" before the product itself: creative, promise, warm-up, paywall, checkout. There is a massive testing surface that does not require deep product releases. A significant portion of B2C revenue comes from experience rather than utility: entertainment, identity, aspiration. This can be delivered through packaging and smart positioning, leaving actual features in the background.
"Retention starts with the first impression. In subscriptions, perceived value matters more than features. If you dig into the data, you can spot a pattern where 70-90% of users barely use the product, yet they still pay. The growth is also driven by scale. The biggest gains come from teams spending heavily and running high-volume funnels."
— David, Head of UA at Talaboos

The trap: if early metrics look good but the product itself delivers little, the effort does not go away. It just gets redirected. You either end up relying on non-transparent billing tactics (making cancellation harder, obscuring renewal dates, hoping for inertia) and then managing the fallout of chargebacks and negative reviews, or you invest permanently in marketing that keeps users emotionally engaged: staying in their field of vision, building community, creating a sense of belonging, constantly reminding them why they are paying. Either way, retention becomes a problem you solve outside the product. The workload of building something valuable does not disappear. It just shifts into marketing, support, and damage control. In subscriptions, renewals are what make the economics work, and without real product value you are always one budget cut or creative fatigue away from losing the user.
The truth, as usual, sits somewhere at the intersection. Here is the combination we have arrived at so far.
MVP = MVS + MLR: a working formula for subscription products
A working hypothesis we landed on through practice: for subscription B2C products in 2026, MVP = MVS + MLR. This may not be a universal formula. But in our vertical, it has been working better than either camp on its own.
MVS (Minimum Viable Signal) is the minimum version that gives you a clear market signal: who your user is, what they respond to, which offer retains them.
MLR (Minimum Lovable Result) is the minimum outcome that feels like real value. The key word here is "result," not "product." The user needs to feel "this is for me" and "I want to continue."
How does this differ from the MLP? MLP can be interpreted as an additional focus on UI, UX, and polish, which may shift priorities away from what matters most at the MVP stage. MLR keeps the focus sharp: the user got what they came for. In microlearning, that means specific content and tangible progress. The shift is subtle, but in practice it changes build priorities: the MVP boundary sits where the user gets a real result.
"If we show a feature in the funnel, it already works in the product. Delivering real expected results from day one is the core principle that reduces chargeback risk, lowers churn, improves rebill rates, and, critically, gives you a clean signal on demand and willingness to pay without noise from disappointed users."
— Alina, Head of PMO at Talaboos
Once the MVP delivers a result, the focus shifts heavily toward marketing.
"Products in the same niche will look more and more alike because nobody is reinventing the wheel. Everyone follows proven patterns. When competitors have roughly the same product, you compete for users through marketing and the most compelling wrapper: creatives, UGC, reviews, positioning, retention."
— Maksim, Product Manager at Talaboos
Layer one: MLR + MVS. The product delivers a result that keeps users around, and through that you get a clear signal on who your user is, what they respond to, and which offer holds. Layer two: marketing and UA. When products in a niche converge, advertising is what determines who captures the user. Without result and signal, marketing won't stick. Without strong marketing and scaling, users won't reach the result.
All of this merges into a single system today. MVP in subscriptions operates as a system that includes:
- Offer and angle: what you promise, how you frame it, which angles convert.
- Acquisition funnel: web funnel, onboarding, warm-up before the paywall.
- Paywall and pricing: plan types, trial vs no trial, price points, checkout.
- First product experience: what the user gets after payment. If this disappoints, chargebacks follow within days.
- Retention signals: does the user come back? D1, D3, D7 as early indicators.
- Renewal and revenue quality: first rebills, refund rate, willingness to pay on the long horizon.
The point of testing all of this together is that no single metric tells the full story. An MVP should validate the system as a whole, and the most important output is early signals of revenue quality: refunds, retention, and first renewals.
An MVP should validate not just payment conversion, but early signals of revenue quality: refunds, early retention, first renewals.
"The earliest signal is trial-to-sub conversion rate. If a user completed the trial and paid, the promise matched the result. The key metrics for our go/no-go decision: CPA, LTV, and ROAS on a 3-4 month horizon. It all comes down to one question: does the acquired user pay back over time. If chargebacks and the percentage of users who actually log in show a problem, no CTR will compensate for that."
— Alina, Head of PMO at Talaboos
Another signal worth tracking alongside payment metrics is organic virality.
"When users start sharing the product on their own, record videos, recommend it in group chats, respond to a request to leave a review, that is a different level of signal. It is not a go/no-go metric yet, but if virality shows up early, the product has landed."
— Maksim, Product Manager at Talaboos
"Speed" changes meaning here. Faster does not mean faster building. It means faster learning. Which audience responds. Which promise converts without toxic side effects. What exactly in the experience creates a winning first impression.
How to balance speed and quality? Communication with users through support, chargeback levels, percentage of users who actually log in, LTV. You need a clear sense of what critically affects user decisions.
Speed of testing vs quality of assumptions
AI has already changed the competitive landscape, and that change is not reversing. Aparna Sinha (SVP of Product at Vercel, ex-Google) laid out the key shifts clearly.
First: your product does not have to be an "AI product," but if you do not understand what AI can do right now, you risk spending months on a feature that users will soon handle (or already handle) with an AI assistant. If you do not understand what the technology can do, you cannot build a product that uses it correctly. She recommends starting with the technology, then mapping it onto user pain points.
Second: team size is no longer a constraint at launch. One person with AI tools now covers work that used to need a team of five. Vercel sees this inside their own company, and chances are you see it too.
Third: the quarterly roadmap has become a document written in pencil. The landscape shifts faster than a quarterly cycle. A fresh example: just this week, Apple started blocking vibe-coding apps that let users create apps directly from an iPhone. No new guidelines were introduced. They simply started enforcing existing rules more strictly. An entire product category (Rork and its competitors) took a hit overnight. If your roadmap was built around that mechanic, it just got wiped.
These three shifts lead to simple math. When the market moves this fast, long-range planning is risky. Spending six months on a big product build means risking that AI tools or a competitor will overtake you while you are still assembling. Predicting what users will need two quarters from now feels more like a lottery than a strategy. So the logic shifts toward a portfolio approach: test many hypotheses in parallel, get market signal fast, invest in what shows results, and shut down what does not. That way you move with the rhythm instead of trying to predict it.
This principle holds for large subscription product teams (we see it across the market and apply it ourselves) and for indie developers. Viktor Seraleev described his journey in an article on IndieHackers: 30+ subscription apps, three fresh starts from zero (Apple removed his developer account twice), growth to $60k MRR. The approach: build many, let the market show what deserves scaling. A portfolio of fast launches gives you a better chance of finding product-market fit than a single "perfect" product that takes six months to ship.
MVP Factory and Scale Lab: building a system for fast product testing
We split product work into two parallel tracks. MVP Factory generates new products for testing. Speed and volume are what matter here. Scale Lab improves products that have already passed validation and are running on traffic. Depth and optimization take over.
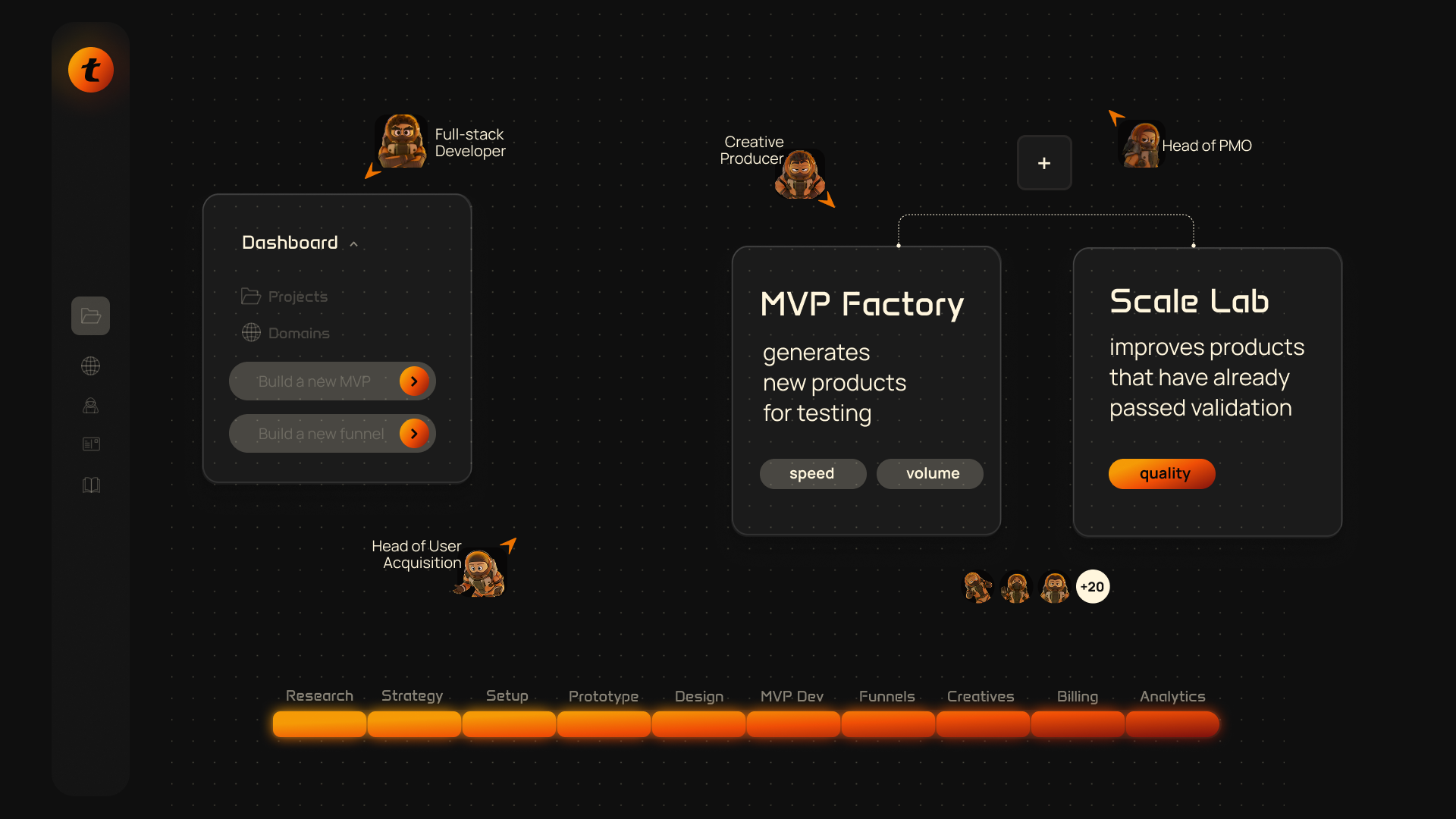
Each track has its own product managers: building new products and scaling existing ones require fundamentally different approaches.
For MVP Factory, the priority is build speed, but speed that does not compromise the quality floor we need for reliable tests. Every MVP has to meet our MVS + MLR standards, otherwise the signals we get from traffic are meaningless. The challenge was how to move fast without cutting corners that affect test validity: demand signal, willingness to pay, early retention.
We found the solution not in growing the team, but in developing our own MVP builder for our product type and microlearning niche. It standardizes assembly, keeps the quality bar consistent across products, and removes the tradeoff between speed and test reliability. The product itself is assembled like a constructor: content, in-product onboarding, mechanics.

"Right now everyone is trying to speed up MVP assembly, mostly through design standardization so you do not get bogged down on the front end, through AI-assisted development, and minimum code from scratch. No-code tools and builders are the baseline accelerator. If there is an option to integrate a feature via API, we integrate. Another important detail: clear role separation within the team, where everyone knows what they own in a given MVP. And the main thing: do not try to create something unique that has never existed. First, feel out the niche with an MVP that combines the best of what competitors offer. Uniqueness comes at the Scale Lab stage, once you have data on what works."
— Alina, Head of PMO at Talaboos
Every product goes through a fixed sequence of stages:
Research → Strategy → Setup and infrastructure → Prototype → Design → MVP Dev → Funnels → Creatives → Billing → Analytics
The output is a complete MVP system ready to run tests: ad accounts, creatives, live web funnels connected to payments, analytics wired at every stage, and a working product on the other end. With this process and approach, the timeline from idea to go/no-go decision is 3-5 weeks.
"7-10 days to build an MVP from scratch, set up funnels, and research the niche. 1.5-3 weeks to establish metric benchmarks, track rebills, reconcile unit economics, and decide whether to scale or stop."
— Alina, Head of PMO at Talaboos
At Talaboos, roughly 75% of our products pass the validation threshold and move to scaling. That does not mean all 75% become profitable businesses. It means 75% show enough signal to justify continued investment. The remaining 25% we shut down quickly, without hesitation. What exactly constitutes 'enough signal'? We use a specific set of criteria that covers acquisition costs, monetization quality, and early user behavior. The exact thresholds and the product-level data behind them are coming in detailed case studies we are preparing now. Here, we focus on the system and framework that produces this hit rate, rather than the individual results.
Scale-up rate stays high in large part because filtering happens not only after launch, but before it.
How to prioritize product hypotheses
"Evaluate the niche first, then build the full product."
— Alina, Head of PMO, Talaboos
Sounds obvious. In practice, most teams do the opposite: they fall in love with an idea first, then look for validation.
At Talaboos, we have a team where everyone brings strong expertise in their own area: product, marketing, UA, development. We believe this combination of perspectives makes hypothesis evaluation more accurate than any single person's judgment. So at the idea selection stage, we want every voice heard. To do this within a structured and manageable framework, we adopted a format that combines individual research with collective evaluation through poker planning. Poker planning is typically used for estimating user stories in development, but we applied it to prioritize and build the roadmap of upcoming product hypotheses.
Step one: individual research.
Every team member (product, marketing, development) independently conducts research and formulates hypotheses for new products. Each person brings their own angle: product looks at user pain points, marketing at traffic costs and creative potential, development at technical feasibility.
Step two: poker planning.
The full team assembles. Each hypothesis gets a brief overview.
- Round one: viability. Everyone scores from 1 to 5. We calculate the median. If the spread is large, we hear from the authors of the highest and lowest scores. Then we revote to make sure the median reflects real consensus, not just an average of extremes.
- Round two: competition and marketing. How crowded the niche is, how expensive and difficult it will be to buy traffic. The UA team has the strongest voice here because they see auction prices and the creative landscape every day.
- Round three: technical complexity. Potential pitfalls from a development, integration, content, and infrastructure perspective. Developers lead this round.
After three rounds, we calculate a combined score and rank the hypotheses.
Step three: deep research on the top 20.
Hypotheses that pass the filter go into detailed investigation. Full competitive analysis, unit economics estimation, content and resource planning.
Step four: roadmap.
Deep research results determine the build and testing queue.

This approach has worked well for several reasons. Three filters (viability, marketing, technical) reduce the likelihood that a weak hypothesis makes it to testing. The UA team flags niches with prohibitive CAC before the first dollar is spent. Developers flag technical risks before the build starts.
The poker format removes the "loudest voice wins" dynamic. Decisions are based on distributed expertise, not hierarchy. The team feels ownership. When you participated in selecting a hypothesis, you work on it differently. This process will evolve as the market accelerates and AI tools mature. AI agents already handle parts of the research: automated review analysis, hypothesis generation. But for now, the go/no-go decision is made by people.
Subscription app market in 2026: key insights from recent reports
In 2026, three major reports on the subscription app market were published: State of In-App Subscriptions 2026 (Adapty), State of Subscription Apps 2026 (RevenueCat), and State of Web2App 2026 (FunnelFox). Together, they provide the most comprehensive picture of the market right now. Here are the key insights worth factoring into your strategy.
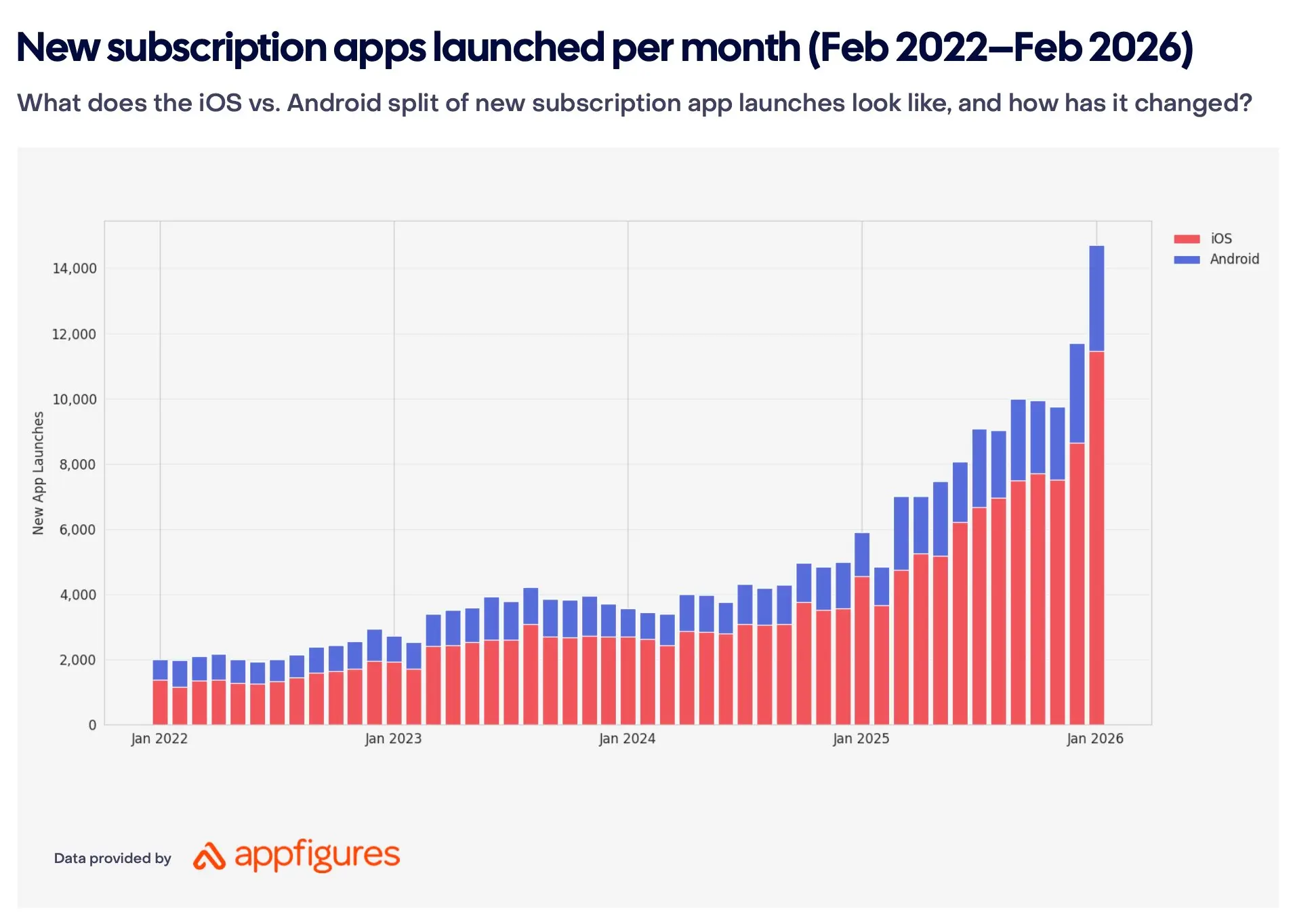
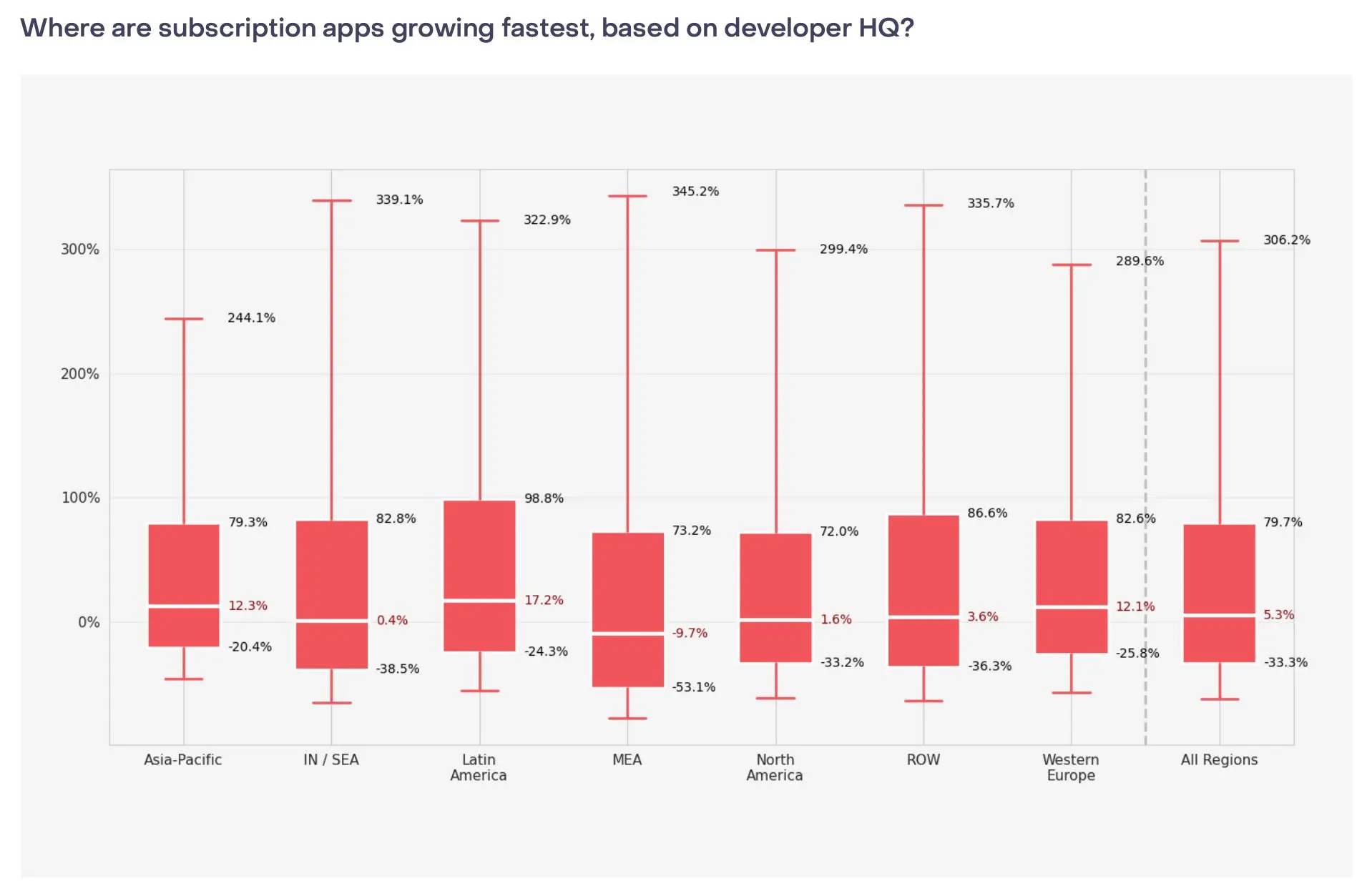
The market is growing, but revenue is concentrating at the top. New subscription app launches grew from 2,000 per month in 2022 to 14,700+ by January 2026 (RevenueCat/AppFigures). The top 10% of apps grew 306% year-over-year, the median managed a modest 5.3%, and the bottom 25% lost 33% of revenue (RevenueCat). 95% of all subscription app revenue sits with the top 10% (Adapty). The gap between leaders and the rest keeps widening.
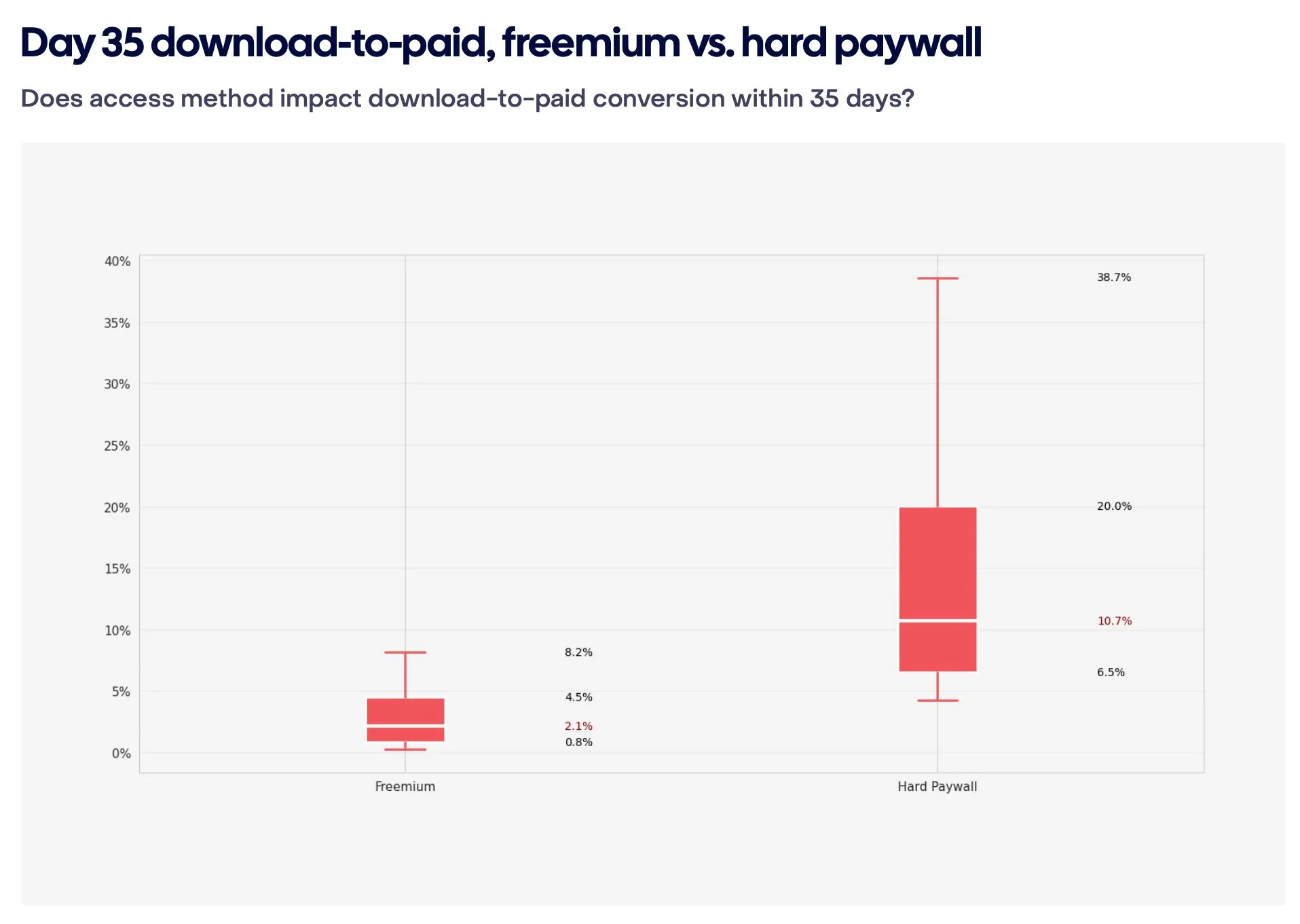
Hard paywalls convert 5x better than freemium: 10.7% vs 2.1% (RevenueCat). Year-one retention is nearly identical between the two. For teams testing hypotheses, a hard paywall at launch delivers a faster, cleaner signal on willingness to pay.
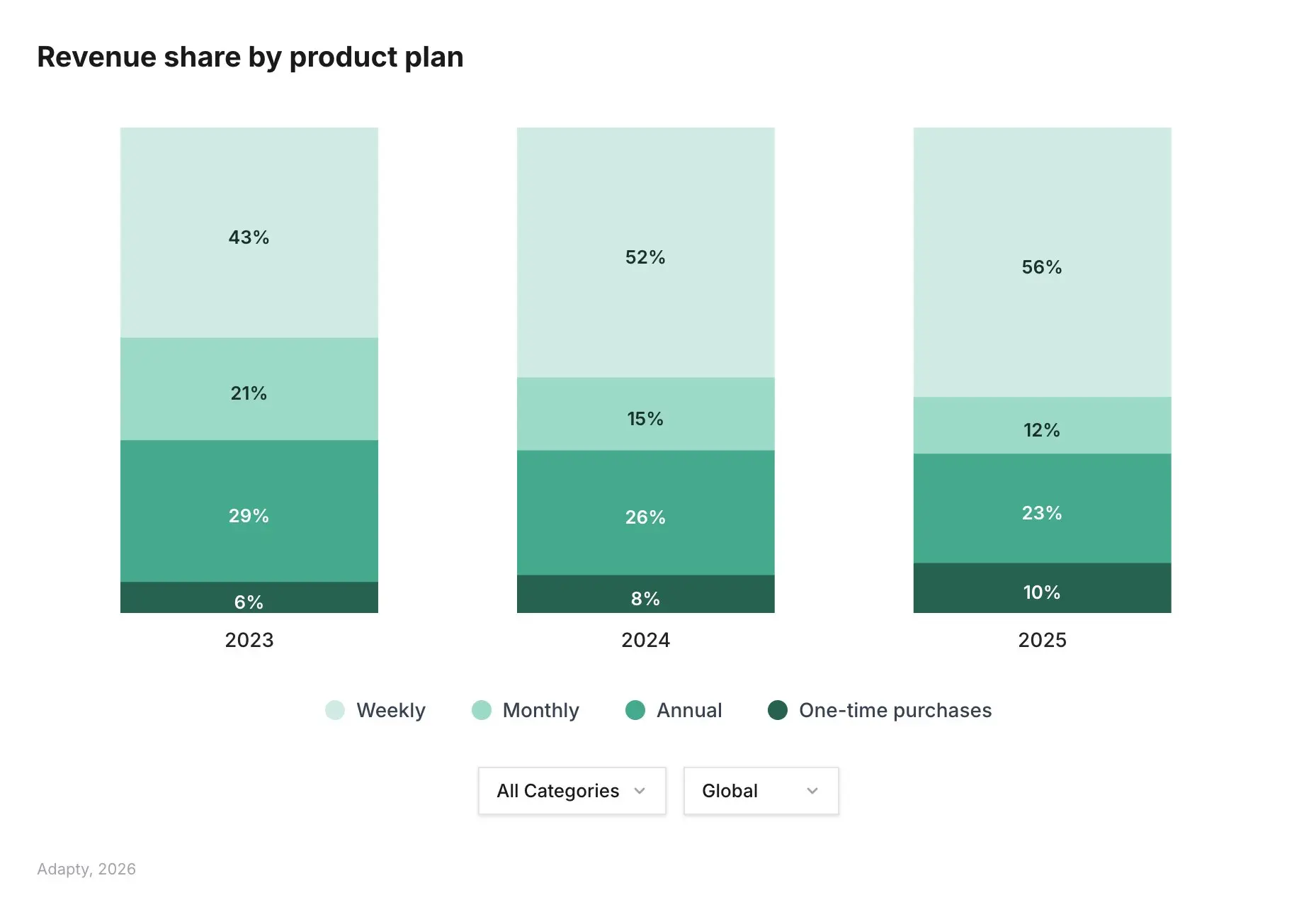
Weekly plans dominate revenue. 55.6% of all subscription app revenue comes from weekly plans (Adapty). Weekly conversion rates are 1.7-7.4x higher than annual. But different verticals adapt the model differently: gaming sells 82% weekly, productivity 77% monthly, health & fitness 68% annual (RevenueCat). There is no one-size-fits-all formula.
Web2app funnels have gone mainstream. 82% of top-grossing apps route subscriptions and payments outside the App Store (FunnelFox). Web conversion is 2x higher than in-app. LTV is 1.5x higher. Among top-revenue apps, 41% already generate part of their revenue through web. Among smaller apps, that figure is just 1.3% (RevenueCat).
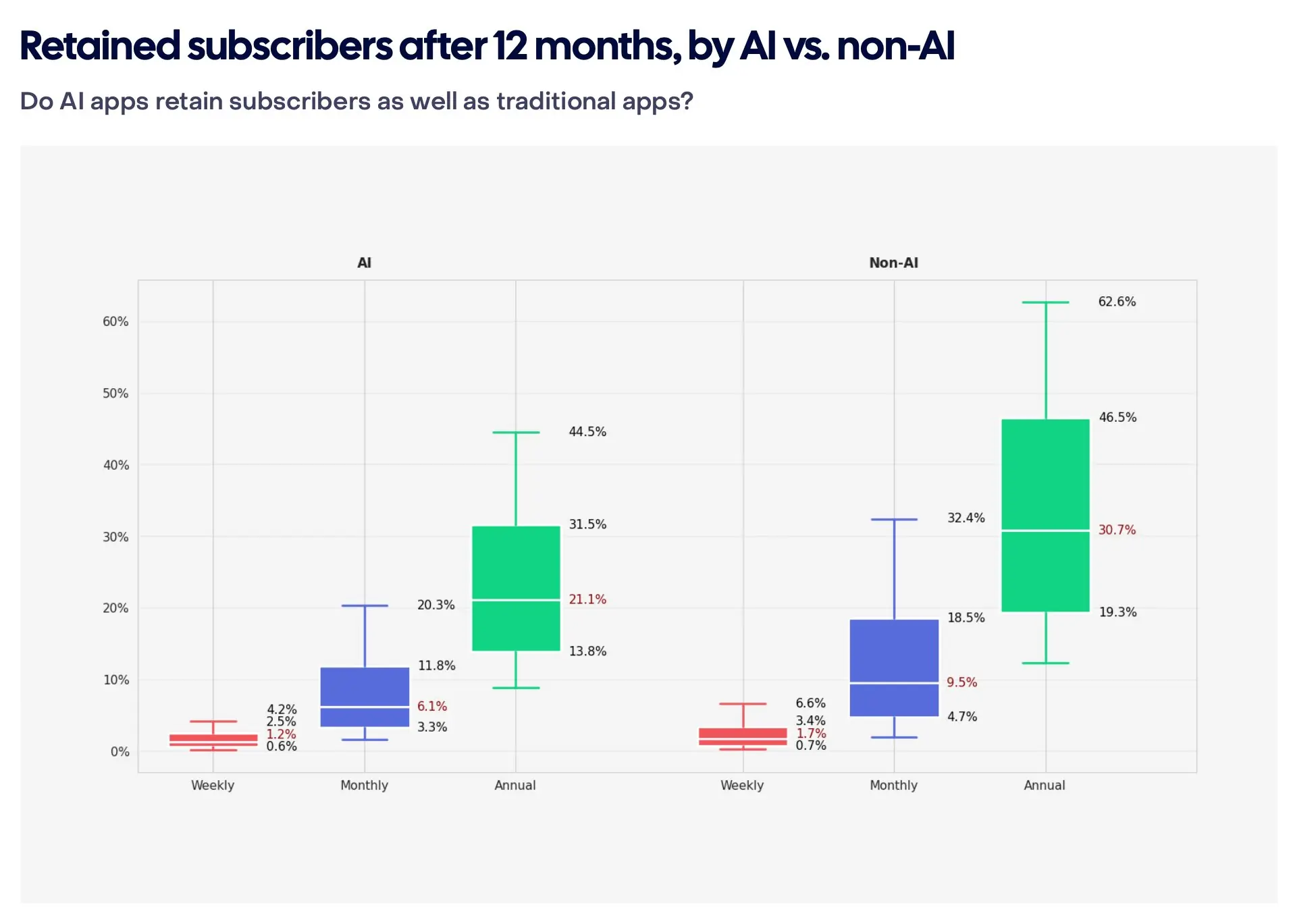
AI apps earn more but lose users faster. AI apps convert from trial to paid 52% better (8.5% vs 5.6%) and monetize downloads 20% more efficiently (RevenueCat). But annual retention for AI apps is 21.1% vs 30.7% for non-AI apps. Users cancel annual subscriptions to AI products 30% faster. Refund rates are higher too: 4.2% vs 3.5% (RevenueCat). Adapty data shows annual plans with trials in AI apps deliver $66.70 one-year LTV vs $49.92 across the market. Higher short-term earnings, faster long-term losses.
Crowded niches demand a differentiator. Health & Fitness is the largest web2app category by volume (FunnelFox) but has the lowest first-renewal retention: 30.3% (Adapty). Over 100,000 subscription consumer apps exist across the stores, fewer than 30 have reached a $1B+ valuation. Without a clear differentiator (audience, format, acquisition channel), the cost of entry will be prohibitive.
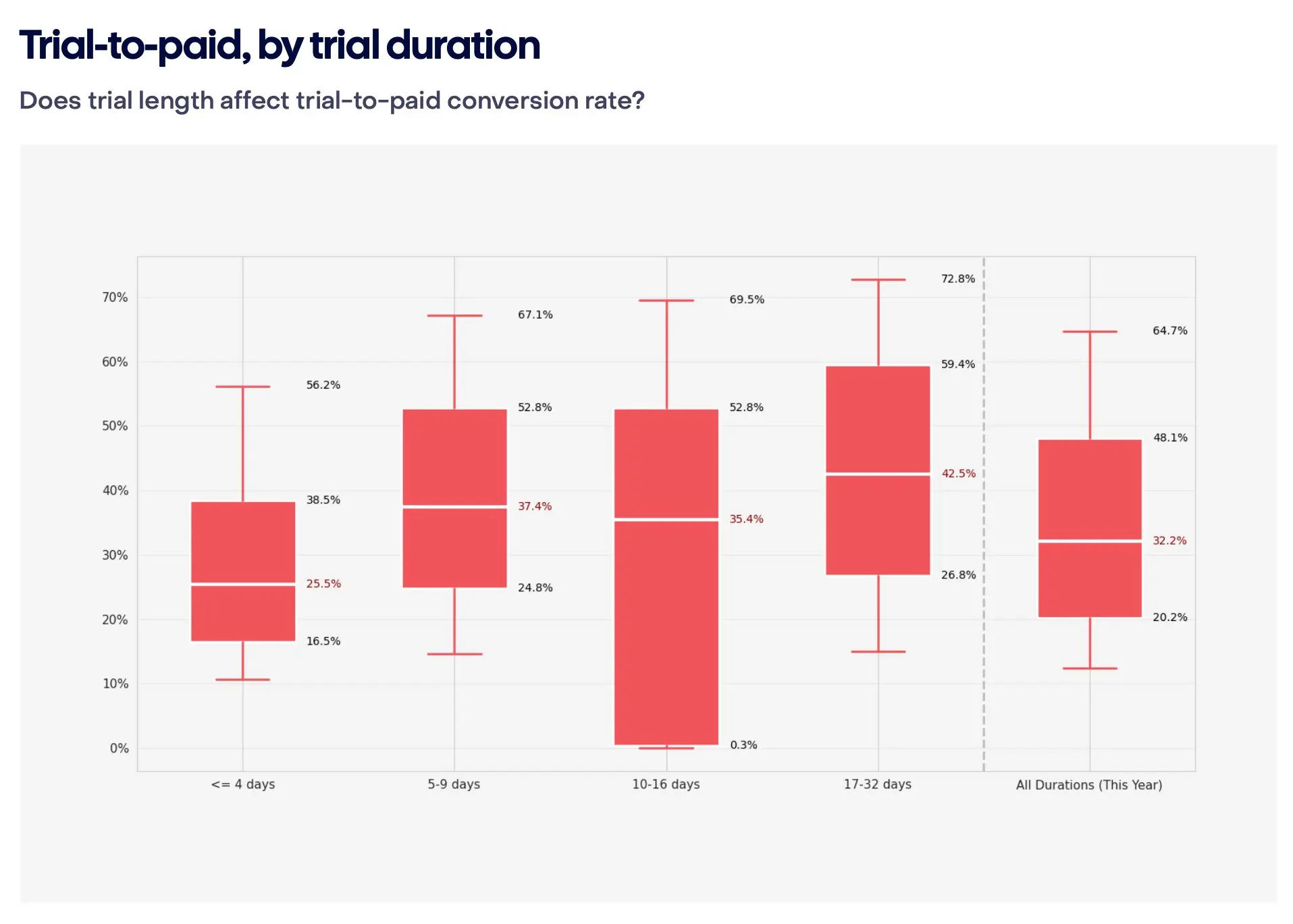
Trials boost LTV but do not always boost conversion. Adapty data shows trial users have 64% higher LTV than direct buyers. But install-to-paid conversion through direct paywalls is often higher than through trial funnels. FunnelFox data confirms that the majority of web2app revenue comes from users who pay upfront, without a trial. Worth testing both rather than committing to one. A separate insight on trial length: subscriptions with 17+ day trials convert 70% better than short ones (42.5% vs 25.5%, RevenueCat). Most teams default to 3-day trials out of habit, but the data suggests at least testing a longer variant.
Legacy apps still capture the bulk of revenue. 69% of all subscription revenue is generated by apps launched before 2020 (RevenueCat). All newer apps combined account for less than a third. For newcomers, the takeaway is clear: a standard "enter and compete head-on" strategy is getting harder to pull off. You need either a portfolio approach with volume of tests, or a precise hit on an underserved niche.
Key takeaways
- Speed of testing appears to beat quality of assumptions. This is not a call to build bad products. More of an observation: teams that build many products quickly and filter by results rather than predictions tend to come out ahead.
- MVP in 2026 = MVS + MLR (at least in our experience). Minimum viable signal + minimum lovable result. UI polish can wait. Delivering the result users came for cannot. After that, the competition for attention runs through marketing.
- Separating generation and scaling helps. MVP Factory and Scale Lab is how we avoid burning out a team that is trying to test new ideas and improve existing products at the same time. Your structure might look different, but the principle of "separate tracks for separate tasks" is worth trying.
- Collective hypothesis selection reduces the error rate at the top of the funnel. Poker planning with three rounds (viability, marketing, technical) has been filtering out weak ideas before we spend a dollar at Talaboos. The format can vary, but the idea of involving UA and dev in evaluation before the build starts seems to work everywhere.
We do not know which product will take off. Experience sharpens intuition, but the market still surprises everyone. The difference is in how fast you find out. At Talaboos, we are building a process where every hypothesis gets its shot, and every test produces data for the next decision. The process itself is still iterating, and we keep changing it.
We have specific case studies and go/no-go criteria behind our 75% scale rate that we are saving for upcoming industry events. If you want the full breakdown of which products passed, which were killed, and exactly what thresholds drove those decisions, follow our updates on LinkedIn. We share real launch cases, tell the story of our journey, and show what works (and what does not) in practice.